
HTTP è l'acronimo di HyperText Transfer Protocol (protocollo di trasferimento di un ipertesto). Usato come principale sistema per la trasmissione di informazioni sul web. è il protocollo standard tramite il quale i server Web rispondono alle richieste dei client. Il protocollo HTTP è basato su un modello richiesta/risposta, quindi ad ogni messaggio di richiesta è associato un messaggio di risposta, anche vuoto. Per demistificare l'idea che http sia un protocollo di comunicazione utilizzabile solo dai browser, è utile fare un po di pratica nell'interazione con i server web, usando strumenti alternativi al browser.
Telnet. è un protocollo client-server basato su TCP. è possibile utilizzare un programma Telnet per stabilire una connessione interattiva ad un qualunque servizio su un server internet. La sintassi per stabilire una connessione è
telnet host port
Con telnet possiamo collegarci ad un server http, costruire le nostre richieste HTTP, inviarle e leggere la risposta. Cominciamo effettuando il collegamento, specificando l'host e la porta (la porta di default per i web server è la 80):
telnet www.google.it 80
Trying 209.85.129.99...
Connected to www.google.it.
Escape character is '^]'.
Una volta stabilita una connessione al server http possiamo inviare una richiesta e ricevere la relativa risposta:
telnet www.google.it 80 Trying 209.85.135.104... Connected to mu-in-f104.google.com (209.85.135.104). Escape character is '^]'. GET /index.html HTTP/1.1 Host: www.google.it Connection: Close HTTP/1.1 200 OK Cache-Control: private, max-age=0 Date: Mon, 26 Jan 2009 09:33:56 GMT Expires: -1 Content-Type: text/html; charset=ISO-8859-1 Set-Cookie: PREF=ID=68f0a6e6797de267:TM=1234361415:LM=1234361415:S=6L8dH9vX0HGcTvJw; expires=Fri, 11-Feb-2011 14:10:15 GMT; path=/; domain=.google.it Server: gws Transfer-Encoding: chunked Connection: Close 1ad4 <html>[.....omissis......]</html> 0
cURL. è un tool per il trasferimento di file su una moltitudine di protocolli di trasporto (http, ftp, ...). La stessa richiesta eseguita in precedenza può esser replicata con cURL in questo modo:
curl www.google.it/index.html
con la possibilità di specificare una serie di opzioni per definizione di header, redirezione dell'output, codifica dei parametri etc... (http://curl.haxx.se/docs/manual.html)
Analizziamo come è strutturata una richiesta HTTP
GET /index.html HTTP/1.1 Host: www.google.it User-agent: Mozilla Accept: text/html, image/jpeg, image/png
La prima è la linea di richiesta: è composta dal metodo, URI della risorsa e versione del protocollo. Il metodo di richiesta, per la versione 1.1, può essere uno dei seguenti:
GET: è usato per ottenere il contenuto della risorsa indicata nell'URI (come può essere il contenuto di una pagina HTML)POST: è usato di norma per inviare informazioni al server (ad esempio i dati di un form)HEAD: funziona come il metodoGET, ma nella risposta vengono specificati solo gli header e non il corpo del messaggio.PUT: questo metodo richiede che il contenuto del messaggio venga memorizzato nella posizione specificata dalla URIDELETE: richiede la cancellazione della risorssa specificata nella URI.TRACE: fa eseguire l'echo del messaggioOPTIONS: richiede al server di fornire informazioni sulle opzioni di comunicazione disponibili per la risorsa specificata.CONNECT: indica al proxy di assumere il comportamento di tunnel
l'URI sta per Uniform Resource Identifier ed indica l'oggetto della richiesta (ad esempio la pagina web che si intende ottenere). I metodi HTTP più comuni sono GET, HEAD e POST. Molte degli altri metodi, anche se definiti nella specifica HTTP 1.1, non sono implementati dalla maggior parte dei web server.
Le linee successive a quella di richiesta sono gli header http. Gli header sono nella forma:
[nome]: [valore]
Di seguito sono riportati alcuni header di uso comune per il messaggio di richiesta. Per una lista completa rimandiamo alle specifiche del W3C.
| Header | Descrizione | Esempio |
|---|---|---|
| Accept | Mime Type accettati nella riosposta | Accept: text/plain |
| Authorization | Credenziali per l'autenticazione | Authorization: Basic QWxhZGRpbcGVuIHNlc2FtZQ== |
| Connection | Tipo di connessione che il client preferisce | Connection: Close |
| Host | Domain name dell'host per il virtual hosting | Host: www.link.it |
Tabella 1. Header HTTP di richiesta
La richiesta che abbiamo inviato in precedenza ritorna una risposta simile alla seguente:
HTTP/1.1 200 OK Cache-Control: private, max-age=0 Date: Mon, 26 Jan 2009 09:33:56 GMT Expires: -1 Content-Type: text/html; charset=ISO-8859-1 Set-Cookie: PREF=ID=68f0a6e6797de267:TM=1234361415:LM=1234361415:S=6L8dH9vX0HGcTvJw; expires=Fri, 11-Feb-2011 14:10:15 GMT; path=/; domain=.google.it Server: gws Transfer-Encoding: chunked Connection: Close 1ad4 <html>[.....omissis......]</html> 0
La prima linea indica la versione del protocollo HTTP, il codice di stato e la Reason Phrase. Il codice di stato è un numero a tre cifre classificabile come segue:
200~299 Successo
300~399 Ridirezione
400~499 Errore del Client
500~599 Errore del Server
Nel nostro caso la richiesta della pagina di root è stata completata con successo, con un 200 ok. Vediamo alcuni esempi di codice di stato che un server può inviarvi. Per la lista completa come sempre rimandiamo al sito del W3C.
200: OK; operazione completata con successo
302: ridirezione a una nuova URL; la URL originale è stata spostata. Non si tratta di un errore, i browser compatibili cercheranno la nuova pagina.
304: usa una copia locale; i browser compatibili mandano una informazione su "lastmodified" della copia della pagina in cache. Il server può rispondere con il codice 304 invece di mandare di nuovo la pagina in modo che il client utilizzi quella che risiede in cache.
401: non autorizzato. L’utente ha richiesto un documento ma non ha fornito uno username o una password validi.
403: Vietato, l’accesso alla URL è vietato.
404: Non trovato; il documento non è disponibile sul server.
500: Server error; si è verificato un errore interno del server.
A seguire la linea di risposta ci sono gli header (opzionali, come per la richiesta) che forniscono utili informazioni sui dati contenuti nel body (tipo, lunghezza), sul server che l'ha costruita, sul file richiesto (data di ultima modifica). Come per gli header di richiesta, segue una lista non esaustiva degli header più comunemente utilizzati:
| Header | Descrizione | Esempio |
|---|---|---|
| Allow | Metodi di richiesta accettati dal server | Allow: GET, HEAD |
| Content-Lentgth | Dimensione dei dati in bytes | Content-Length: 258 |
| Content-Type | Mime type del contenuto della risposta | Content-Type: text/html; |
| Date | Data e ora dell'invio della risposta | Date: Tue, 15 Nov 1994 08:12:31 GMT |
| Exprires | Data di scadenza del documento | Expires: Tue, 15 Nov 1994 08:12:31 GMT |
| Last-Modified | Data dell'ultima modifica effettuata sulla risorsa | Last-Modified: Tue, 15 Nov 1994 08:12:31 GMT |
| Location | Per il redirect | Location:http://isi.link.it/isi.html |
| Server | Contiene informazioni sul server | Server:Apache/1.3.29 (Unix) PHP/4.3.4 |
| WWW-authenticate | Contiene informazioni per l'accesso in caso di errore 401 | WWW-Authenticate: Basic realm="link-it" |
Tabella 2. Header HTTP piu frequenti
Dopo gli headers c'è una linea vuota a separare i dati (opzionali, come per
la Richiesta). Questi possono essere in qualsiasi formato, anche binario, come
specificato nell'header ContentType. Nel nostro caso, avendo richiesto una
pagina HTML, il ContentType è text/html e nel corpo del messaggio vediamo il
codice della pagina.
Per effettuare le nostre richieste faremo uso principalmente dei metodi GET o POST. La differenza sostanziale sta nel modo in cui i dati sono codificati nel messaggio. Per la GET sono incapsulati nella URI di richiesta, mentre per la POST sono inclusi nel corpo del messaggio.
Si possono compattare più parametri nella query string usando una codifica standard:
separare i parametri con &
sostituire i blank con +
sottoporre ad escape (%xx) i caratteri speciali
www.host.com/page?param1=value1¶m2=value2
Per convenzione, il metodo GET dovrebbe essere usato solo per reperire risorse, mentre la POST usata per richieste che modificano lo stato del server.
Proviamo ad esempio ad eseguire una ricerca su Google con Telnet. La pagina di ricerca
è www.google.it/search mentre il parametro da inviare si
chiama q.
telnet www.google.it 80
Trying 209.85.129.99...
Connected to www.google.it.
Escape character is '^]'.
GET /search?q=ciao HTTP/1.1
Host: www.google.it
Connection: Close
Nel caso di una richiesta con metodo POST, dopo gli header c'è una linea vuota seguita dai dati della richiesta. Nel caso di GET o HEAD il campo body della richiesta è vuoto non avendo dati da inviare.
Un'altro modo per inserire i parametri è quello delle form html, usato normalmente per la navigazione web.
Le Form sono introdotte dal tag <form>. Oltre a codice html, possono contenere i
seguenti tag:
<input>definisce text entry fields, checkboxes, radio buttons o pushbuttons<select>definisce dropdown menus e selection box<textarea>definisce campi text-entry su più linee
la Form può avere i seguenti attributi:
action, la URL di destinazione a cui saranno inviati i datimethod, il metodo HTTP usato per la sottomissione dei dati (get o post)
Vediamo ad esempio il codice di una semplice form che invia un parametro via get:
<form action="http://projects.cli.di.unipi.it/isi/cgi-bin/env.pl" method="GET">
Parametro: <input type="text" name="par">
<br/>
<input type="submit" value="Invia">
</form>
Tramite browser, sarà visualizzato un campo di input testuale ed un bottone.

Il testo inserito nel campo di input verrà adeguatamente codificato e inviato via GET
alla pagina http://projects.cli.di.unipi.it/isi/cgi-bin/env.pl, uno script che ritorna
tutte le informazioni utili riguardo la richiesta ricevuta e il server che lo ospita:
SCRIPT_NAME = /isi/cgi-bin/env.pl SERVER_NAME = projects.cli.di.unipi.it HTTP_REFERER = http://localhost:8080/sample/ SERVER_ADMIN = wwwadm@cli.di.unipi.it HTTP_ACCEPT_ENCODING = gzip,deflate HTTP_CONNECTION = keep-alive REQUEST_METHOD = GET HTTP_ACCEPT = text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5 SCRIPT_FILENAME = /home/projects/isi/cgi-bin/env.pl SERVER_SOFTWARE = Apache/2.2.3 (Debian) mod_ssl/2.2.3 OpenSSL/0.9.8c HTTP_ACCEPT_CHARSET = ISO-8859-1,utf-8;q=0.7,*;q=0.7 QUERY_STRING = par=Bed+%26+Breakfast REMOTE_PORT = 47261 HTTP_USER_AGENT = Mozilla/5.0 (X11; U; Linux i686; it; rv:1.8.1.16) Gecko/20080715 Fedora/2.0.0.16-1.fc8 Firefox/2.0.0.16 pango-text SERVER_PORT = 80 SERVER_SIGNATURE = Apache/2.2.3 (Debian) mod_ssl/2.2.3 OpenSSL/0.9.8c Server at projects.cli.di.unipi.it Port 80 HTTP_CACHE_CONTROL = max-age=259200 HTTP_ACCEPT_LANGUAGE = it-it,it;q=0.8,en-us;q=0.5,en;q=0.3 HTTP_COOKIE = SESSa20d042eca1ead7ca16668c646e4e3af=07a100cd31837a1b1588bb2bd08e38a0 REMOTE_ADDR = 212.171.49.34 HTTP_KEEP_ALIVE = 300 SERVER_PROTOCOL = HTTP/1.0 PATH = /usr/local/bin:/usr/bin:/bin REQUEST_URI = /isi/cgi-bin/env.pl?par=Bed+%26+Breakfast GATEWAY_INTERFACE = CGI/1.1 SERVER_ADDR = 131.114.120.130 DOCUMENT_ROOT = /home/projects/ HTTP_HOST = projects.cli.di.unipi.it
Abbiamo usato fin qui telnet per effettuare le richieste ai web
service, ma vediamo come eseguire le stesse interrogazioni programmando un semplice
client HTTP in java.
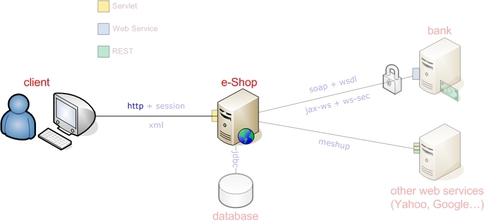
Ci sono più classi che consentono di effettuare comunicazioni su protocollo HTTP, aiutando a vario titolo il programmatore la gestione della specifica nelle operazioni più complesse. Il package che più si avvicina alle nostre esigenze è Commons-HttpClient (http://hc.apache.org/index.html) del progetto Jakarta Commons.
Implementiamo un client che replica la richiesta fatta in precedenza tramite la form inviando come valore Bed & Breakfast, stampando richiesta e risposta HTTP. I passi da completare sono i seguenti:
Costruire la query string.
Costruire e stampare la richiesta GET.
Eseguire la richiesta e ricevere la risposta.
Stampare il messaggio di risposta.
Il primo passo richiede di inserire un parametro nella query string, come abbiamo fatto negli esempi precedenti. La difficoltà sta nel fatto che nel parametro da passare ci sono caratteri che non possiamo inserire nella query string (il carattere & e gli spazi per l'esattezza) quindi dobbiamo prima codificari. Vediamo come fare:
String parameter = URLEncoder.encode("Bed & Breakfast");
String queryString = "http://localhost:8080/sample/index.html?par=" + parameter;
Adesso possiamo costruire e stampare la richiesta:
HttpClient httpclient = new DefaultHttpClient();
// Prepariamo la richiesta
HttpGet httpget = new HttpGet(queryString);
// Stampiamone il contenuto
System.out.println(httpget.getRequestLine());
Header[] headers = httpget.getAllHeaders();
for(int i=0; i<headers.length; i++){
System.out.println(headers[i].getName() + ": " + headers[i].getValue());
}
Eseguiamo la richiesta e stampiamo la risposta.
// Eseguiamo la richiesta e prendiamo la risposta
HttpResponse response = httpclient.execute(httpget);
// Stampiamo Status Line e Headers
System.out.println(response.getStatusLine());
headers = response.getAllHeaders();
for(int i=0; i<headers.length; i++){
System.out.println(headers[i].getName() + ": " + headers[i].getValue());
}
// Prendiamo il contenuto della risposta
HttpEntity entity = response.getEntity();
InputStream instream = entity.getContent();
String s = null;
BufferedReader reader = new BufferedReader(new InputStreamReader(instream));
while((s = reader.readLine()) != null) System.out.println(s);
instream.close();
Non rimane che gestire eventuali errori sincerandoci di chiudere la connessione se attiva.
Un Web Server implementa il protocollo HTTP lato server. Il suo compito è quello di ricevere le richieste dai vari client. La porta solitamente utilizzata per questo scopo è la 80. Il browser non richiede che venga specificata e usa quella porta come default per individuare il server. Qualora la porta del Web Server fosse diversa, allora è necessario specificarla nell'url (es. http://www.link.it:8080/isi.html) Ricevura la richiesta, il server si occupa di reperire le risorse specificate nella URL di richiesta secondo il metodo specificato (GET, POST..). A questo punto costruisce un prologo di risposta HTTP contenente informazioni sullo stato, gli header e i dati relativi alla risorsa richiesta. Completata la risposta la invia al richiedente.
I servlet sono oggetti che operano all'interno di un server per applicazioni (Application Server, per esempio Apache Tomcat) e potenziano le sue funzionalità.
La parola servlet fa coppia con applet, che si riferisce a piccoli programmi scritti in Java che si eseguono all'interno di un browser. L'uso più frequente dei servlet è generare pagine web in forma dinamica a seconda dei parametri della richiesta spedita dal browser. Un servlet può avere molteplici funzionalità e può essere associato ad una o più risorse web.
Un esempio potrebbe essere un meccanismo per il riconoscimento dell'utente. Quando digito un URL del tipo miosito/login, viene invocato un servlet che verificherà che i dati inseriti siano corretti e in base a questa decisione mi potrà indirizzare in una pagina di conferma o di errore.
Sotto quest'ottica un servlet è un programma che deve rispettare determinate regole e che processa in un determinato modo una richiesta HTTP. Nulla vieta che all'interno dello stesso server web possano girare più servlet associati a URL diversi; ognuno di questi servlet farà cose diverse e estenderà le funzionalità del server web.
La Servlet API (http://java.sun.com/products/servlet/2.2/javadoc/index.html) è un'estensione standard di Java sin dalla versione 1.2 e si tratta di moduli caricati dinamicamente dal server su richiesta. Una servlet è in grado di gestire più richieste contemporaneamente in modalità thread safe, consentendo a più processi di uilizzare le stesse risorse gestendone la concorrenza.
La diffusione di questa tecnologia garantisce una buona portabilità del codice su un elevato numero di ambienti, aspetto cruciale quando si parla di applicazioni internet.
Spesso le servlet sono indirizzati tramite il prefisso servet nella URL
http://hostname:port/servet/Servlet.class[?args]
Il prefisso è configurabile nell'application server ed è possibile avere più prefissi sul solito application server.
Una servlet, nella sua forma più generale, è un'istanza di una classe che
implementa l'interfaccia javax.servlet.Servlet. Molte servlet,
comunque, estendono una delle implementazioni standard di questa interfaccia.
Dovendo gestire richieste HTTP,
useremo ed esamineremo l'implementazione javax.servlet.http.HttpServlet.
Quando viene istanziata/deployata una HttpServlet, l'application server (es.
Tomcat) chiama il metodo init della Servlet. La Servlet dovrebbe così
effettuare una procedura di startup unica nel suo ciclo vitale. Adesso la Servlet è
pronta per ricevere le richieste, per ognuna delle quali viene invocato il metodo
corrispondente al tipo di richiesta (doGet, doPost, doHead...).
![[Nota]](./stylesheet-images/note.png) |
Nota |
|---|---|
La servlet viene chiamata concorrentemente per gestire più richieste,
quindi dovrebbe essere implementato in modo threadsafe.
Qualora non fosse possibile gestire la concorrenza dei thread e
si rivelasse necessario rendere la Servlet singlethreaded è sufficiente che
implementi l'interfaccia |
. Quando è necessario effettuare l'unload della servlet (ad esempio perchè è
stata rilasciata una nuova versione, o il server deve essere spento) viene chiamato
il metodo destroy.
public class MyServlet extends HttpServlet{
... ...
@Override public void init() throws ServletException{
// Viene eseguito una sola volta
// alla prima chiamata della servlet
}
@Override public void destroy(){
// Viene eseguito una sola volta
// all'unload della servlet
}
... ...
}
Adesso che abbiamo chiaro il ciclo di vita di una Servlet, possiamo implementarne
una Servlet Http. javax.servlet.HttpServlet è l'implementazione
dell'interfaccia Servlet che dobbiamo estendere facendo l'override dei metodi
ereditati. I metodi della classe HttpServlet ricevono in ingresso gli oggetti
HttpServletRequest e
HttpServletResponse che forniscono metodi per reperire o
impostare i dati della richiesta e risposta HTTP.
public class MyServlet extends HttpServlet{
... ...
@Override public void doGet(HttpServletRequest req, HttpServletResponse res){
...
}
@Override public void doPost(HttpServletRequest req, HttpServletResponse res){
...
}
@Override public void doPut(HttpServletRequest req, HttpServletResponse res){
...
}
@Override public void doDelete(HttpServletRequest req, HttpServletResponse res){
...
}
... ...
}
Se non viene fatto l'override di un metodo, viene usata
l'implementazione ereditata che di default risponde al client con un errore di tipo
501: Not Implemented. Qualora il metodo fosse implementato, ma non
ammesso per la risorsa richiesta, il server deve rispondere con un errore 405:
Method not allowed.
Ottenuta una HttpServletRequest è possibile in ogni metodo:
getParameterNamesaccede alla lista dei nomi dei parametrigetParameteraccede ai parametri per nomegetQueryStringconsente il parsing manuale della QUERY_STRING
Vediamo come implementare una servlet http che raccolga i dati inviati dal client.
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class HelloServlet extends HttpServlet {
@Override public void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
String nome = req.getParameter("nome");
System.out.println("Hello, " + parameter);
}
}
Una volta compilata la servlet dobbiamo "confezionarla" per essere passata all'Application Server. Questa è la stuttura standard per le applicazioni web compatibili J2EE 1.2:

Per quanto riguarda il nostro esempio, dobbiamo mettere la classe
appena compilata che implementa la servlet sotto WEB-INF/classes e
creare il file WEB-INF/web.xml. Vediamone un esempio:
<web-app>
<servlet>
<servlet-name>hello</servlet-name>
<servlet-class>HelloServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>hello</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
L'elemento servlet definisce il nome della servlet da usare per
riferirla nel resto del documento e la classe che la implementa. L'elemento
servlet-mapping indica al server a quale URL il servizio deve
rispondere.
Completati i file necessari e organizzati secondo le specifiche, copiamo tutto
nella cartella webapps di Tomcat per fargli eseguire il deploy
dell'applicazione.
Da html.it
Una delle funzionalità più richieste per un'applicazione web è mantenere le informazioni di un utente durante tutta la sessione. Una sessione è una sequenza di transazioni http, legate tra di loro secondo una logica applicativa. Sappiamo che il protocollo http non ha stato e per il server non è possibile capire se due richieste http sono eseguite dal solito client. Per aggirare questo problema, il server associa e comunica ad un client un identificativo di riconoscimento che questo userà per le richieste successive, permettendo al server di riconoscerlo. È possibile quindi creare applicazioni su protocollo http che riconoscono l'utente, che tengono traccia delle sue scelte e dei suoi dati.
Vediamo come nasce una sessione e come il server riesce ad associare la solita sessione ad un client usando i cookies:
Prima Richiesta.
L'utente contatta il server per la prima volta.
Il server controlla se il client ha fornito un SessionID. Se non lo ha fatto crea una nuova sessione e genera un SessionID per identificare questa sessione.
Il server invia un header
Set-Cookieal clientIl client salva il cookie per il dominio in questione
Seconda Richiesta.
L'utente visita il server, stavolta inserendo l'header
Cookiecontenente il SessionID salvato in precedenza.Il server controlla se il client ha fornito un SessionID.
Il server verifica se il SessionID ricevuto corrisponde ad una sessione.
Il server localizza i dati di sessione e li rende disponibili all'applicazione
|
Nota |
|---|---|
|
I cookie HTTP sono frammenti di testo inviati da un server ad un Web client e poi rimandati indietro dal client al server
- senza subire modifiche - ogni volta che il client accede allo stesso server. Il server invia l'header
Il client risponde con l'header
|
Se il client non supporta i cookies, possiamo comunque trasmettere l'identificativo di sessione in altri due modi:
Hidden Field: come parametro nel payload del messaggio HTTP
Url Rewriting: nella URL di richiesta con la sintassi
http://host/resorce;JSESSIONID=idsessione?param=value&..
Le informazioni di sessione sono quindi memorizzate sul server, mentre lato client viene visto solo un identificativo di sessione.
|
Nota |
|---|---|
Per scoprire se un client supporta o meno l'uso dei cookies, non c'e' altro modo che eseguire un tentativo di scrittura di cookie e verificarne successivamente l'invio da parte del client. Poichè questo controllo introduce dei passaggi extra non desiderati nel processo di accesso e fruizione di una applicazione web con sessioni, spesso si preferisce inviare l'id sessione contemporaneamente via cookie che via hidden field. Le richieste successive paleseranno quale dei due metodi il client ha accettato. |
Quando sviluppiamo una applicazione web dobbiamo sempre ricordare che l'utente non necessariamente segue il percorso che abbiamo immaginato, ma che possa saltare passaggi, inserire dati errati, concorrere con altri utenti nell'uso di risorse condivise.
Alitalia ci fornisce un esempio di cattiva programmazione nell'uso delle sessioni. Vediamo come replicarlo. Andiamo sulla pagina delle prenotazioni e facciamo una ricerca, ad esempio per un volo A/R Roma - Milano:


In un'altra finestra facciamo un'altra ricerca, ad esempio per un volo A/R Roma - Napoli:


Torniamo adesso alla lista dei voli Roma - Milano e acquistiamo il primo.
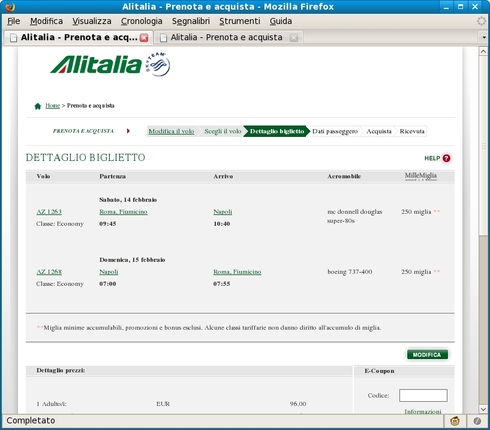
Ci aspettavamo il riepilogo del volo Roma - Milano, ma ci arriva quello di Roma - Napoli. Cosa è successo? Se guardiamo il sorgente della pagina che mostra i voli disponibili vediamo che ad ogni bottone è associato il numero di indice in tabella. Se ne desume che in sessione è salvata una corrispondenza che associa al numero di indice l'identificativo del volo. Quando abbiamo fatto la seconda ricerca quei valori sono stati sovrascritti annullando di fatto la prima ricerca. Il progettista del sito non ha tenuto conto della possibilità che un utente potesse fare ricerche multiple concorrentemente. Una soluzione banale al problema è di non riferire un volo con l'indice di tabella, ma con un identificativo univoco.
In Java una sessione HTTP viene rappresentata tramite un oggetto
HttpSession. Tramite le sessioni si realizza la persistenza degli
oggetti tra una richiesta HTTP e l’altra. Java tenta di gestire le sessioni tramite
cookie. Se questo non è possibile si può alternativamente
passare l’ID di sessione tra i parametri della pagina. Per questo scopo, il metodo
encodeURL(String URL) di HttpServletResponse aggiunge il parametro
con l’id di sessione all’URL passata nel caso in cui questo sia necessario. Tramite
il metodo getSession() in HttpServletRequest viene restituita la
sessione corrente o ne viene creata una nuova se questa non esiste.
Modifichiamo il servlet creato in precedenza e implementiamo uno storico dei parametri passati.
//Recupero la sessione o la creo se non esiste
HttpSession session = request.getSession();
//Recupero la lista di parametri in sessione o la instanzio se ancora non esiste
String parameters = (String) (session.getAttribute("parameters"));
//Aggiungo il parametro arrivato nella lista di parametri e li stampo a video
parameters += myParameter + "\n";
System.out.println(parameters);
//Inserisco la lista dei parametri aggiornata in sessione.
ses.setAttribute("parameters", parameters);
Lato client dovremo recuperare l'id di sessione e inserirlo nelle richieste successive o tramite header o tramite query string.
//Recupero l'id sessione dagli header della risposta
HttpResponse response = httpclient.execute(httpget);
String cookie = response.getHeader("Set-Cookie");
//Inserisco l'idSessione nelle richieste successive
HttpRequest request = ....
request.setHeader("Cookie", cookie);
In questo modo tutte le volte che effettueremo una richiesta inviando l'id di sessione e un valore ad un parametro, riceveremo nella risposta tutti i valori inviati fino a quel momento.



