
Diritto d'autore © 2005-2016 Dip. di Informatica - Università di Pisa
- 1. Architetture Applicative
- 2. Il Protocollo HTTP e la programmazione di Servlet
- 3. Introduzione all'XML
- 4. Web Service
- 5. Sicurezza nelle applicazioni WEB
- 6. Gestione del Backend
La rapida diffusione di Internet ha provocato una vera e propria rivoluzione nelle architetture delle applicazioni distribuite, aumentando significativamente la complessità dei sistemi in gioco.
E' sicuramente interessante, prima di approfondire gli aspetti architetturali tipici di una applicazione Internet, ripercorrere rapidamente l'evoluzione delle architetture dei sistemi distribuiti negli ultimi anni.
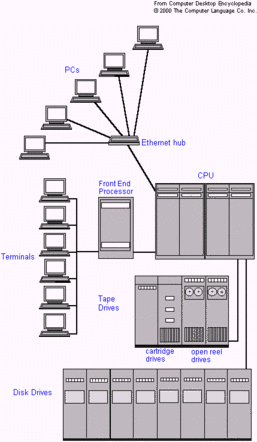
Inizialmente, quelle che oggi chiamiamo Applicazioni Enterprise (come ad esempio i sistemi di prenotazione, o il software di gestione degli ATM) non erano realizzati come oggi in maniera distribuita ma erano invece applicazioni monolitiche ospitate da un Mainframe. L'interazione da pate degli utenti (o meglio degli operatori) avveniva da terminali, tipicamente i 3270 a fosfori verde sempre più difficili da trovare in circolazione, connessi al Mainframe via cavi coassiali. I terminali non avevano alcuna capacità di elaborazione locale dei dati e si limitavano a trasmettere al mainframe i dati digitati dall'utente e a visualizzare sul display i caratteri ricevuti dal mainframe.
A quei tempi la scalabilità di un'applicazione, cioè la sua capacità di incrementare nel tempo la propria capacità di risposta in funzione delle necessità e delle disponibilità di risorse, era quindi unicamente di tipo verticale, basata cioè sulla capacità di incrementare la potenza di calcolo del mainframe.
Un primo cambiamento radicale si ebbe con la diffusione, avvenuta nel corso degli anni '80, di due tecnologie ancora oggi estremamente diffuse: i database relazionali e i personal computer.
I personal computer offrivano sia potenza di calcolo a basso costo che i primi tool per lo sviluppo di interfacce grafiche.
I Data Base Management System (DBMS) d'altro canto offrivano uno strumento affidabile ed a basso costo per la gestione delle transazioni applicative.
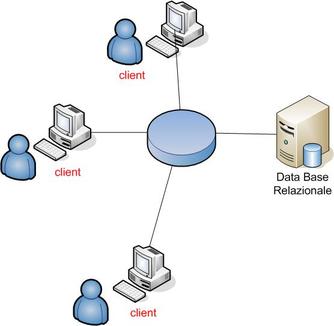
Si diffuse così un nuovo paradigma applicativo, solitamente riferito come client-server, basato proprio sull'uso coordinato di queste due tecnologie:
il client, detto anche Fat Client a causa delle sue dimensioni notevoli, include l'interfaccia utente (presentation logic), la logica applicativa del programma (business logic) e la logica di elaborazione dei dati (data manipulation logic);
il DBMS si limita inizialmente a gestire la manipolazione dei dati in maniera transazionale.
Il nuovo paradigma si diffonde con una straordinaria rapidità, grazie alla sua caratteristica di sfruttare il parallelismo nel più semplice dei modi, distribuendo cioè l'esecuzione della maggior parte del carico sui PC degli stessi utenti.
La semplicità dell'architettura client-server, che ne ha costituito il principale punto di forza, mostra però nel tempo alcuni limiti importanti. In particolare:
l'uso di un Fat Client richiede un upgrade del client ad ogni modifica dell'applicazione (nuove feature e/o bug-fix);
se è vero, come abbiamo detto, che il client scala ottimamente sui PC utilizzati al crescere del numero di utenti, la stessa cosa non succede però per il DBMS, che tende a diventare un collo di bottiglia dell'intera architettura.
Per risolvere questo problema ci si comincia a muovere verso il concetto di quello che oggi viene chiamato Application Server. Si tratta sostanzialmente di spostare parte della logica applicativa dal client al server. I vendor più importanti si muovono quindi in due direzioni:
I produttori di DBMS cominciano ad aggiungere funzionalità applicative nei loro prodotti, nella forma di trigger e stored procedure.
I produttori dei TP Monitor, i framework applicativi (come li chiameremmo oggi) che dominavano il mercato Mainframe, colgono l'opportunità per portare i loro software su sistema Unix, avviando il processo di downsizing da mainframe a un ambiente etorogeneo, che usa estesamente minicomputer, reti LAN e personal computer.
Queste due strade si rilevano però pocò più che un palliativo. I DB server, che già costituivano un collo di bottiglia dell'intera architettura, vedono aumentare il loro carico di lavoro. I TP Monitor, anche in ambiente Unix mantengono significative controindicazioni in termini di costi e complessità d'uso.
In questa fase intervengono altre due significative novità destinate ad influenzare l'evoluzione delle architetture applicative:
da una parte si sviluppa un'attenzione crescente verso gli aspetti di portabilità, standardizzazione ed interoperabilità, poi scaturita nella definizione di Open Systems;
si afferma decisamente il paradigma di programmazione ad oggetti e, di conseguenza, cominciano ad affermarsi tecnologie per la distribuzione degli oggetti in rete.
Lo sforzo più significativo per la costruzione di un sistema ad oggetti distribuito si sviluppa nell'ambito dell'OMG (Object Management Group), un'organizzazione che raggruppa tutti i più importanti player del mercato del software e che arriva a standardizzare l'architettura software CORBA (Common Object Request Broker Architecture), un'architettura ad oggetti distribuita, definita da OMG, come segue: a vendor-independent architecture and infrastructure that computer applications use to work together over networks. Using the standard protocol IIOP, a CORBA-based program from any vendor, on almost any computer, operating system, programming language, and network, can interoperate with a CORBA-based program from the same or another vendor, on almost any other computer, operating system, programming language, and network.
CORBA ha poi effettivamente ottenuto un ampio successo, diventando uno standard di fatto nel mondo Enterprise per la realizzazione di applicazioni multi-linguaggio e multi-piattaforma.
è in questo contesto che esplode la novità della tecnologia Internet, trainata dal travolgente successo del World Wide Web. La rete Internet in effetti esisteva già da tempo ma viene scossa dall'invenzione del WWW, un nuovo paradigma progettato per la visualizzazione di testi ipermediali in rete, e basato sull'uso del protocollo HTTP e dei Browser Web, utilizzati per la visualizzazione di pagine descritte tramite il linguaggio HTML.
l'architettura WWW prevede infatti l'uso del protocollo http per le comunicazioni tra il Browser ed il Web Server. Il Web Server serve direttamente al Browser le informazioni statiche, prelevandole dal proprio file system, ma può anche utilizzare il protocollo CGI per richiedere ad applicazioni esterne di generare dinamicamente le informazioni (tipicamente pagine html ed immagini) da restituire al browser.

A mano a mano che il Web si diffonde su Internet, e che si comincia a costruire siti web dinamici, ci si rende conto che questo semplice modello architetturale avrebbe potuto essere utilizzato anche per la realizzazione di vere e proprie applicazioni distribuite.
I primi siti web dinamici utilizzavano infatti il browser non solo per visualizzare le pagine html, ma anche per raccogliere le preferenze dell'utente, ad esempio per il login o per le selezioni della pagina, tramite l'uso del costrutto FORM del linguaggio HTML. Il browser si dimostra così adatto a gestire il livello di presentazione, prima occupato dal Fat Client nell'architettura client server.
Dal punto di vista del backend, invece, questi siti cominciano ad accedere sempre più intensamente a varie fonti informative (data base ed in generale sistemi legacy), tramite l'uso di applicazioni CGI, per costruire le pagine html da restituire come risposta al Browser.
Ne deriva un'architettura applicativa nella quale:
il browser tende a diventare un Client Universale, con la sola funzione di gestire l'interazione con l'utenza;
il web server si candida ad assumere la funzione di "Application Server", mediando le interazioni tra il browser e gli ulteriori livelli di backend applicativo (DBMS e sistemi legacy);
il protocollo http si candida a diventare lo standard di fatto per tutte le comunicazioni applicative veicolate tramite Internet;
nel backend continuano a vivere sia i DBMS acceduti dalle estensioni Web tramite middleware basati sul linguaggio SQL (odbc, jdbc, ...), sia le applicazioni legacy vere e proprie, più (CORBA, RMI, DCOM) o meno (RPC, API proprietarie, ...) recenti.
Questa nuova architettura si afferma rapidamente, identificata inizialmente come Architettura a Tre Livelli (Three Tier Architecture). Successivamente, a mano a mano che si intesifica la disponibilità e l'uso di Servizi Internet, si evolve verso un'architettura a più livelli (Multi Tier Architecture), schematizzata nella figura successiva, che prevede sia interazioni verso il backend che verso servizi esterni disponibili anch'essi tramite Internet.
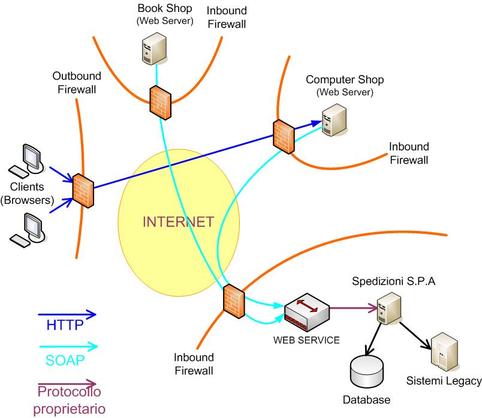
La diffusione di Internet si porta dietro tutto un fiorire di nuove tecnologie. Sostanzialmente si fa strada l'idea che se la tecnologia Internet si è dimostrata adatta a supportare lo straordinario successo del WEB, scalando su milioni di server e di utenti diversi, può essere una tecnologia di successo anche per le applicazioni distribuite.
Nascono quindi tutta una serie di nuove proposte, che ruotano principalmente attorno all'uso di XML per la rappresentazione dei dati di interscambio e l'uso di http per il livello di trasporto fisico dei pacchetti xml.
Nel loro insieme queste tecnologie vanno oggi sotto il nome di Web Services, e si differenziano in due proposte diverse.
La prima, spesso riferita semplicemente come Web Services è basata sull'uso del protocollo SOAP, di cui parleremo estesamente più avanti, per l'imbustamento dei contenuti applicativi, e sulla definizione di numerosi e spesso eccessivamente complessi formati di header della busta SOAP, utilizzati per contenere le metainformazioni necessarie a vari servizi di infrastruttura (sicurezza, indirizzamento, transazionalità, etc.).
La seconda, solitamente riferita come Restful Web Services o semplicemente REST parte invece dall'assunzione che il protocollo http possa essere usato nativamente per realizzare applicazioni, senza bisogno dell'ulteriore livello di imbustamento SOAP.
REST impone però un insieme di vincoli molto rigidi alla progettazione delle applicazioni ed è stato spesso oggetto di vere e proprie guerre di religione tra i puristi del paradigma e coloro i quali utilizzavano il termine REST semplicemente per indicare una qualunque applicazione http che non utilizzasse il protocollo SOAP. Nel post seguente del 2008, Roy Fielding, l'autore della proposta REST, stigmatizza in maniera abbastanza decisa la sua irritazione per questo tipo di aberrazione dell'architettura REST e ne ribadisce i principali vincoli.
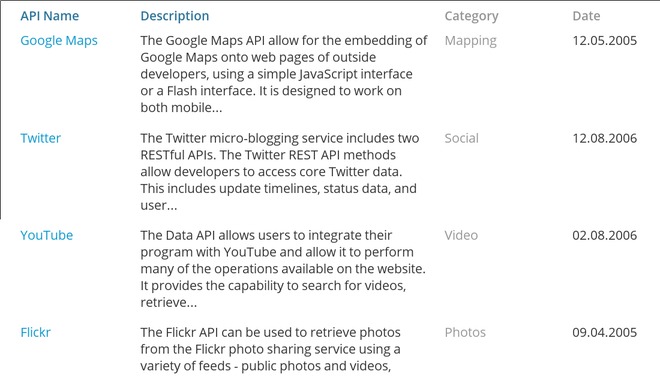
Di recente si è così diffusa il nuovo termine di Web API o addirittura semplicemente API per indicare una qualunque modalità di interazione applicativa basata sul protocollo http. La figura che segue mostra il trend di diffusione dei 3 termini di cui sopra negli ultimi anni.
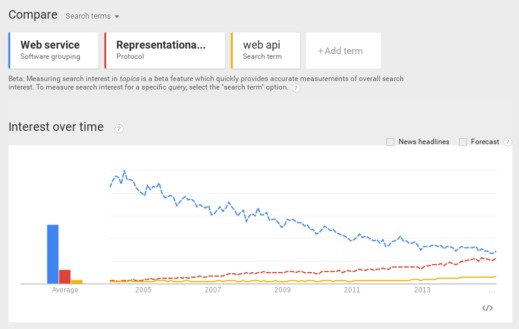
In tutte queste diverse interpretazioni, i Web Services si stanno diffondendo moltissimo come tecnologia per la realizzazione delle Architetture Service Oriented (SOA), un paradigma di progettazione applicativa basato sul concetto di servizio, considerato da tempo il paradigma emergente nelle architetture applicative, e che ha finalmente trovato nei Web Services un'adeguata tecnologia attuativa. Oggi praticamente tutti i principali portali applicativi, forniscono le stesse funzionalità anche tramite API. La figura che segue mostra alcune tra le API più accedute oggi su Internet.
Abbiamo visto come si siano diffusi una serie di nuove possibilità per la realizzazione delle interfacce applicative dei servizi, sostanzialmente basate su protocollo http ed interscambio di dati in formati come XML e JSON.
La forte evoluzione delle applicazioni su Internet ha comportato però esigenze del tutto nuove anche nelle infrastrutture utilizzate per il rilascio in produzione di tali applicazioni, facilmente intuibili considerando la quantità di utenti potenziali delle applicazioni e soprattutto di dati su cui tali applicazioni debbono poter operare.
Abbiamo già detto di come i DBMS relazionali, pur essendo un elemento imprescindibile di qualunque architettura applicativa su Internet, costituissero tuttavia un potenziale collo di bottiglia di tali applicazioni. L'architettura a 3 livelli ha permesso di scaricare il DB da qualunque logica applicativa, ma lascia il DB come elemento unico di sincronizzazione dei vari nodi del cluster degli Application Server del secondo livello. E sappiamo che questo può avere un forte impatto sulle prestazioni complessive dell'applicazione, principalmente a causa delle difficoltà di scalare orizzontalmente tipica degli engine transazionali.
D'altra parte le nuove applicazioni Internet hanno requisiti prestazionali incommensurabilmente maggiori delle applicazioni tradizionali ed hanno richiesto quindi soluzioni innovative anche per quanto attiene alle tecnologie di gestione dei dati.
Queste problematiche sono state tradizionalmente gestite con varie tecniche di partizionamento dei dati. è possibile in questo modo replicare lo stesso schema dati su più server DBMS, da utilizzare per la memorizzazione di partizioni diverse dei dati applicativi (ad esempio partizionando i clienti sulla base della regione di appartenenza ed assegnando ogni partizione).
L'esperienza di YouTube fino al 2008, descritta a questa url (http://highscalability.com/youtube-architecture), costituisce un interessante esempio di come un semplice partizionamento dei dati sulla base dell'identificativo incrementale degli utenti dell'applicazione abbia permesso di migliorare sensibilmente le prestazioni complessive.
Tecniche di partizionamento dei DBMS sempre più evolute, implementate a livello applicativo utilizzando installazioni multiple su server diversi dello stesso prodotto, o implementate a livello del DB engine utilizzando versioni distribuite dello stesso DBMS, hanno permesso una effettiva scalabilità orizzontale della gestione dei dati applicativi.
Tuttavia i dati a cui le applicazioni Internet hanno bisogno di accedere aumentano costantemente: immaginiamo ad esempio la necessità di Google di indicizzare tutti i dati del web, o la nuova esigenza, sempre più sentita di analizzare i commenti sui Social Network per interpretare la pubblica opinione sui temi più disparati (Sentiment Analysis). Le prestazioni possibili con le tradizionali tecniche di indicizzazione e di accesso ai dati sono inadatte per queste nuove esigenze e portano quindi a tecnologie del tutto nuove.
Nell'ottobre del 2003 Google annuncia il Google File System (http://research.google.com/archive/gfs.htmlhttp://research.google.com/archive/gfs.html);
Nel dicembre del 2004 Google annuncia MapReduce (http://research.google.com/archive/mapreduce.html);
Nell'insieme queste due tecnologie permottono a Google di utilizzare una modalità molto più efficiente di indicizzazione dei dati Web, a volte sintetizzata con il suggestivo slogan "bringing the code to the data". Si tratta di un'estremizzazione delle tecniche di partizionamento del dato, con le applicazioni strutturate in due fasi: la fase di "map" che vede un unico processo, in esecuzione parallela su tutti i nodi del cluster, operare sui dati installati localmente a quel nodo. La fase di "reduce" che prevede l'aggregazione dei dati elaborati dai vari nodi nella fase di map al fine di produrre i risultati finali del calcolo (tipicamente il risultato di una query). La significativa novità è costituita dal fatto che nella fase di map, la più complessa dal punto di vista del calcolo, i dati sono dislocati sugli stessi nodi del cluster (tutti dotati di ampi server locali) dove gira il codice applicativa, annullando così i significati overhead di trasmissione tra applicazioni e DB engine delle architetture DBMS tradizionali.
Google File System e Map reduce aprono la strada ad Hadoop, una distribuzione software completa costruita per supportare i nuovi scenari di Big Data analysis, come nel frattempo il marketing ha sapientemente ribattezzato questo tipo di applicazioni. Su Hadoop si sono concentrati alcuni tra i maggiori investimenti della storia recente dell'informatica, sicuramente gli unici di così grande dimensione relativi a tecnologia pura e non a servizi di successo. Non ci addrentriamo per ora nella descrizione di questa complessa architettura, tuttora in rapida evoluzione, ne sentiremo parlare ancora a lungo.
Anche fuori dal mondo hadoop si manifestano nel frattempo le più disparate esigenze di utilizzo di dati molto meno strutturati di quanto non permettessero le rigide schematizzazioni richieste dai DBMS relazionali (si pensi a dati JSon o XML o anche a semplici documenti binari). Nasce inoltre l'esigenza di memorizzare una enorme quantità di dati e quindi di essere in grado di scalare tali dati su cluster di grande dimensione. Queste nuove esigenze portano allo sviluppo di una nuova ed articolata tipologia di DB engine, nel loro insieme etichettati come Database NOSQL. Il termine, inizialmente derivato dal fatto che tali DB avevano interfacce di interrogazione proprietarie, esplicitamente progettate per lo specifico tipo di dati da gestire, è stato nel tempo interpretato come "Not Only SQL Database", a mano a mano che questi prodotti hanno cominciato a supportare SQL come interfaccia di interrogazione. Al contrario di quello che accade per i DBMS tradizionali, queste query sono tipicamente tradotte in vere e proprie applicazioni distribuite sui vari nodi del cluster che costituisce il DB.
Il motivo dell'efficienza dei DB NOSQL e della loro capacità di scalare ottimamente su cluster di grandi dimensioni è stata tipicamente dovuta (almeno inizialmente) al fatto di aver rilasciato alcuni dei vincoli di consistenza supportati dai DBMS relazionali e di supportare specifiche tipologie di dati (ad esempio con tecniche di memorizzazione basate su grafi).
Di fronte alla diffusione dei DB NOSQL, non si è fatta attendere la reazione dei principali attori del mercato DB, che hanno coniato la nuova keywork NEWSQL ad indicare nuove versioni dei propri prodotti relazionali, in grado, almeno sulla carta, di assicurare le stesse prestazioni e scalarità dei nuovi DB NOSQL ma mantenendo tutte le tradizionali caratteristiche dei loro prodotti consolidati.
Abbiamo visto nelle sezioni precedenti come le Applicazioni Internet si presentino come un insieme di nodi applicativi che interagiscono tra loro utilizzando la tecnologia dei Web Services.
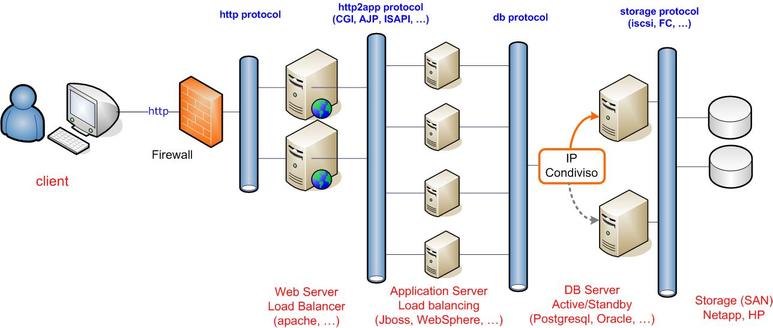
In questa sezione vogliamo cominciare ad analizzare il dettaglio di un singolo nodo applicativo che, da un punto di vista logico, può essere schematizzato come nella figura successiva.

Nella figura successiva mostriamo invece come i 3 livelli logici del singolo nodo applicativo vengano effettivamente realizzati in un reale progetto attuativo.
Ogni livello è a sua volta composto da alcuni componenti software, che interagiscono tra loro come schematizzato nella figura che segue.
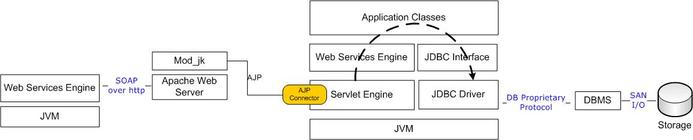
è facile immaginare come la progettazione, la realizzazione ed il tuning di un'applicazione Internet non possano non essere condizionati dalla complessità dell'ambiente in cui queste stesse saranno poi ospitate e dalle interazioni che dovranno avere con componenti esterni. L'obiettivo di questo corso è proprio quello di introdurre alle problematiche specifiche che un progettista, uno sviluppatore ed un sistemista applicativo dovranno imparare a fronteggiare, lavorando con questa tipologia ormai estremamente diffusa di applicazioni.



